
.png)

Python Web Scraping using BeautifulSoup
- NABANITA MISHRA

- Jul 10, 2021
- 3 min read
What would you do if you have to pull a large number of data from websites without manually doing it? Well, my answer to that is "Web Scraping." Web Scraping just makes your job easier and faster. In this blog, I will highlight web scraping briefly and demonstrate how to extract data from an e-commerce website.
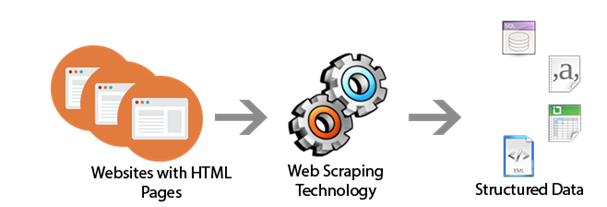
So web scraping is an automated process used to extract a massive amount of data from websites. Generally, data on the websites are unstructured, and web scraping helps collect the unstructured data and store it in a structured format.
There are multiple ways to scrape websites, such as online Services, APIs, or writing your code. Here, we'll see how to implement web scraping with the Python BeautifulSoup library.
Purpose of using?
So why does someone have to collect such extensive data from websites? To know more about this, let's look at some of its applications:
Price comparison: Services use web scraping to collect data from online shopping websites and compare the prices of products.
Research and Development: It is also used to collect a large set of data (Statistics, Temperature, General Information, etc.) from websites, which are analyzed and used to carry out Surveys or for R&D.
Email address gathering: Most companies that use email as a medium for marketing use web scraping to collect email IDs and send bulk emails.
Job listings: Details regarding interviews, job openings are collected from different websites and then listed in one place to be easily accessible to the user.
Social media scraping: It can collect data from Social Media websites to figure out what's trending.
How to Scrap data?
When you run the appropriate code, eventually, a request is sent to the URL of the website. As a response to the request, the servers allow reading the HTML page. The code then parses the HTML page and extracts the data.
Now let's go through some mandatory steps to extract required data from an e-commerce website:
Step 1: Import all the necessary libraries:
In my further demonstration, I will be using the following Python libraries :
BeautifulSoup: Beautiful Soup is a Python package for parsing HTML documents. It generates trees that are helpful to extract the data easily.
Urllib.request: Urllib module is the URL handling module in python. urllib.request is a package of it used to define functions and classes to open URLs (mostly HTTP). One of the most straightforward ways to open such URLs is: urllib.request.urlopen(url)
import bs4 import BeautifulSoup as soup
import urllib.request import urlopen as uReqFirst, let's create a Python file with a .py extension.
I am going to scrap the following URL to get the Price, Name, and RAM size of multiple laptops in a structured format -
my_url = 'https://www.amazon.in/s?k=laptop&ref=nb_sb_noss_2'
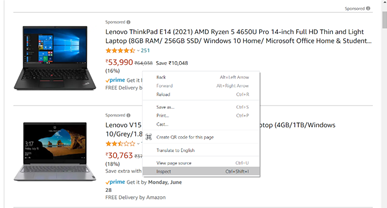
Step 2: Inspecting the Webpage:
The HTML page is usually nested in tags. So, we inspect the page to see under which tag the required data is nested. To inspect the page, just right-click on the element and click on "Inspect." Then you get to see a "Browser Inspector Box" open.
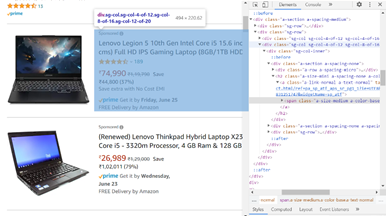
Step 3: Get the HTML:
Let's extract the Price, Name, and RAM, which are in the "div" tag, respectively.
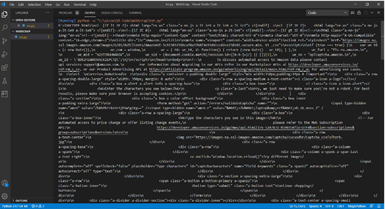
Step 4: Parce the HTML :
Refer to the below code to open the URL:
uClient = urllib.request.urlopen(my_url)
page_html = uClient.read()
uClient.close()
page_soup = bs4.BeautifulSoup(page_html, "html.parser")
containers = page_soup.findAll("div", {"class": "_1AtVbE col-12-12"})
container = containers[0]
# print(container.div.img['alt'])
price = container.findAll("div", {"class": "col col-5-12 nlI3QM"})
# print(price[0].text)
RAM = container.findAll("div", {"class": "gUuXy-"})
# print(RAM[0].text)The following unstructured data will be generated on the default terminal after parsing the HTML page -
Step 5: Extract and store the data:
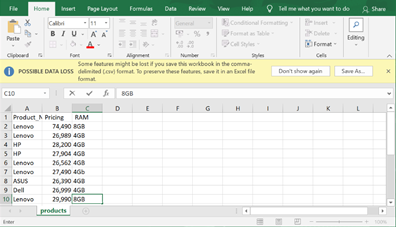
After extracting the data, it needs to be stored in a sorted manner; this format can be varied depending on the user's requirement. To do this, I am creating a CSV file named <product.csv> by adding the following lines to the code:
filename = "products.csv"
f = open(filename, "w")
headers = "Product_Name, Pricing, RAM\n"
f.write(headers)
for container in containers:
product_name = container.div.img["alt"]
price_container = container.findAll("div", {"class": "col col-5 12 nlI3QM"})
price = price_container[0].text.strip()
RAM_container = container.findAll("div", {"class": "gUuXy-"})
RAM = RAM_container[0].text
print("product_name:" + product_name)
print("price:" + price)
print("RAM:" + RAM)This CSV file will be generated automatically in the default folder fetching all the scraped data.
I hope this small snippet was informative and added some value to your learning; we can also explore it with different modules and applications of python in the upcoming blog.



Comments